This post was adapted from a talk called "String Theory", which I co-presented with James Edward Gray II at Elixir & Phoenix Conf 2016. I originally posted it on the Big Nerd Ranch blog. My posts on Elixir and Unicode here and here were also part of that talk.
IO Lists and Phoenix
In my last post, I showed how Elixir's IO lists enable us to build and write output with minimal work and memory usage.
This is nice enough for writing files, but it's absolutely killer for web applications. On any given web page, you probably have some elements that are dynamic, like the current user's name, or a list of recent posts, or some items in a shopping cart.
But those dynamic bits of data are wrapped in chunks of markup that always look the same: maybe each product is wrapped in a
Suppose you have a template called
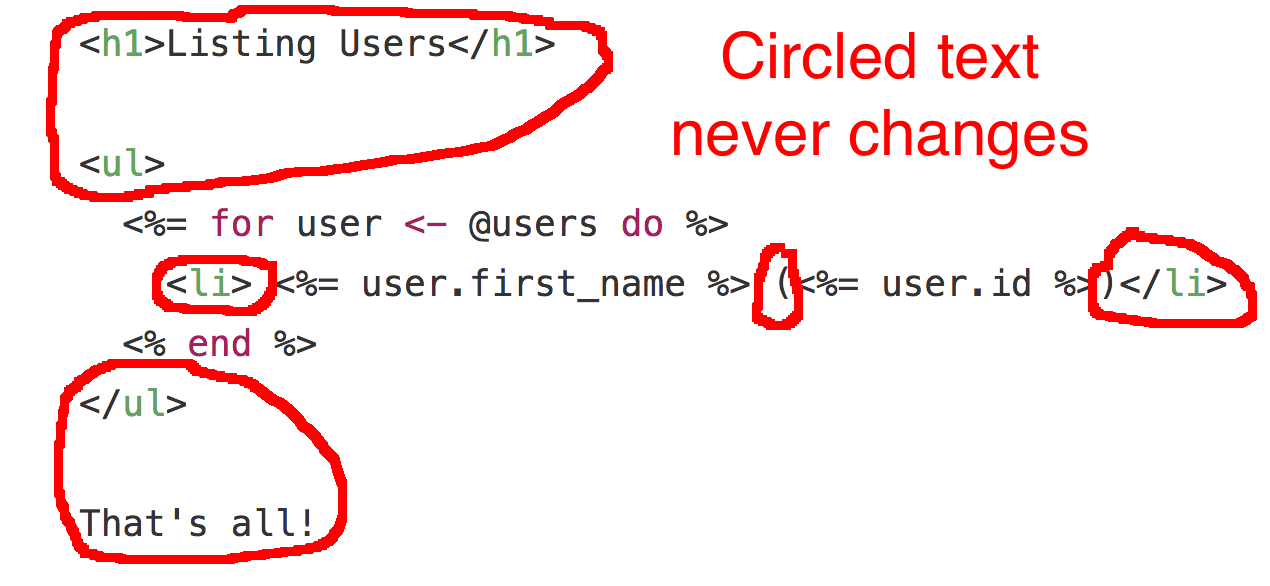
These strings are going to be needed over and over again. The circled text never changes:
Most web frameworks concatenate the static markup and the dynamic data into one big response string.
That concatenation is a lot of work, and it creates a lot work for the garbage collector, too.
By contrast, Phoenix does the following:
The generated function will look something like this (don't worry about the details):
The thing to notice in that function is that it contains some string literals, like
When the function runs, it will return an IO list like this:
You may notice that this IO list looks odd.
That's because it's not a "proper" list.
We often build lists by prepending items, like this:
Every item in this list is itself a list, with a head pointing to a string and a tail pointing to another list.
The final list is an empty one (though it's not shown).
That's a lot of lists!
But it's also possible to do this:
This is an "improper list" because the head points to "A", and the tail does not point to a list, but to "B".
Many functions that expect lists will break if given an improper one, so it's not a good idea to use them, generally speaking.
But in this case, because the only thing we'll be doing with these lists is wrapping them in other lists and ultimately writing them to a socket, making them improper removes the need to allocate quite so many lists.
OK, moving on.
The really interesting thing is what happens next: the IO list is handed to the web server process, which sends it to the user by calling
Remember, the minimum requirement for sending a web response is to copy each byte of the response to the socket. With this view rendering strategy, that's basically all Phoenix is doing.
There's one other great thing about this way of building responses.
Remember this template, where some of the strings will be needed over and over again?
As we saw, the function that Phoenix compiles to render that template will use the same strings in memory every time, simply adding the dynamic parts as needed to the IO list.
This is, in effect, a kind of view caching.
You may have used web frameworks with slower, concatenation-based view rendering, which try to compensate by adding ways to cache views and partials.
But they make you solve one of the hard problems in computer science: cache invalidation.
You have to take into account the fact that content changes over time.
For example, a blog post may get updated in the database.
You might handle this with a simple expiration time: "cache this post partial for 1 hour."
Or you might tie the view cache to the state of your database.
For example, "the HTML for a blog post and its comments can be cached, but we have to re-render it if the post changes, or if its comments change, or if the name of the post's author changes, or if the name of any of the comments' authors change."
These kinds of rules may be needed for Rails' Russian Doll Caching.
Also, you have to deal with the fact that parts of the page vary per user; for example, they might display the current user's email address, or recommended products.
You might solve this by having a per-user cache key, as the Django docs show, or by caching some generic version and using JavaScript to add personalized content after the page loads, as was suggested years ago.
Or you might just forego caching for that part of the page.
In any case, you're responsible for specifying which parts of your view can be cached and under what circumstances the cache is valid.
The more frequently-updated your content is, the less these caches help you, and the more personalized it is, the more space they occupy in your cache store.
Did I mention that you have to have a cache store?
You have to decide whether that should be in RAM, or the file system, or an external database, with the tradeoffs those choices imply.
I don't mean to be too harsh.
Smart developers have put lots of hard work into making those view caches easy to use.
But there's still a lot to think about.
By contrast, by compiling templates to functions, Phoenix automatically and universally applies this simple view caching strategy: the static parts of our template are always cached.
The dynamic parts are never cached.
The cache is invalidated if the template file changes.
The end.
Now, since the dynamic parts of a view (like the list of blog post titles from your database) are never cached in the view functions, they need to be given that data at render time.
If database queries are your performance bottleneck, you could cache their results; you might, for example, use a materialized view for that, and have a process responsible for periodically refreshing it.
But that would be a completely separate concern from your templates.
And Phoenix's view rendering will almost certainly be too fast for you to care to cache its final product.
Before we wrap up, I want to add a small disclaimer about system calls.
As we saw in my last post, small strings (less than 64 bytes long) are generally combined by the BEAM in the
For example, here's a trace I ran of a Phoenix app with some very large strings in its templates.
The two strings highlighted in blue were large ones that appeared multiple times in the template.
In writing the response to the socket, Cowboy referenced those same strings in memory each time.
The string highlighted in red is the opening
But regardless of how the BEAM writes Phoenix's responses to the socket, we certainly benefit from the fast, memory-efficient way that they're built in the first place.
So the next time you see Phoenix render your web page in less than a millisecond, take a moment to appreciate the lovely little IO lists that help make that possible.users/index.html.eex that looks like this: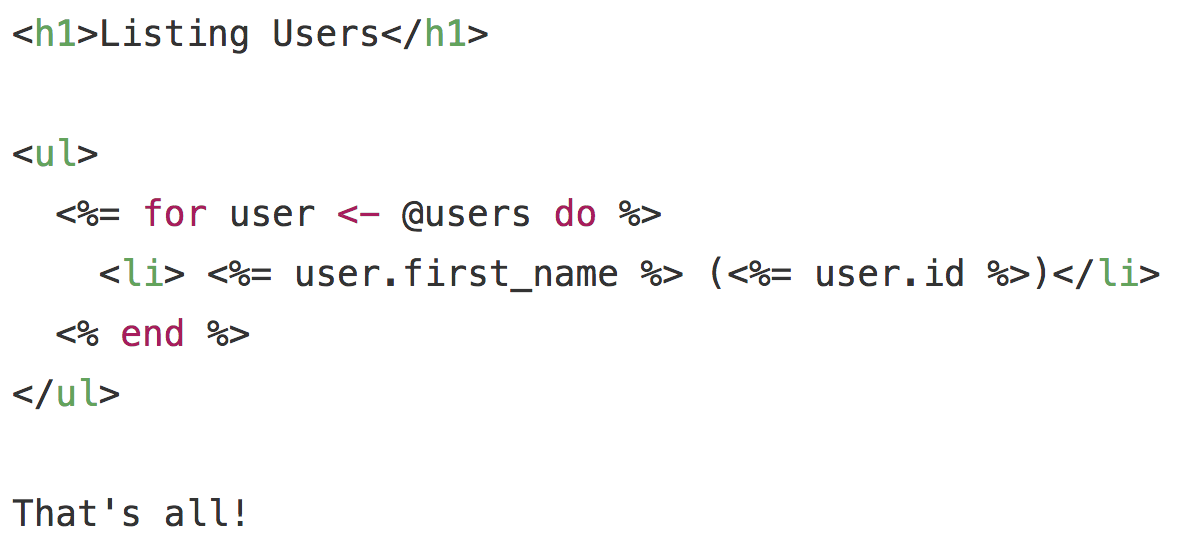
users/index.html.eex (among others) EEx to compile it, along with its layout and partials, into a function EEx to do that) UsersView.render("index.html", assigns) defmodule MyApp.SomeView do
defp(index.html(var!(assigns))) do
_ = var!(assigns)
{:safe, [(
tmp1 = ["" | "Listing Users
\n\n\n "]
[tmp1 | case(for(user <- Phoenix.HTML.Engine.fetch_assign(var!(assigns), :users)) do
{:safe, [(
tmp1 = [(
tmp1 = ["" | "\n
\n\nThat's all!\n"]}
end
def(render("index.html", assigns)) do
index.html(assigns)
end
end" and Listing Users
\n\n\n "
"\n .
These will be the same immutable strings, at the same locations in memory, every time they appear in the returned IO list, request after request.[[["" | "Listing Users
\n\n\n "],
[[[[["" | "\n
\n\nThat's all!\n"]list = [] # => []
list = ["C" | list] # => ["C"]
list = ["B" | list] # => ["B", "C"]
list = ["A" | list] # => ["A", "B", "C"]list = ["A" | "B"] # => ["A" | "B"]writev on the network socket. The only place the full response is created is in the socket buffer.
Cache Flow
A Disclaimer
writev arguments.
So if you trace a Phoenix app, you probably won't see every little handed to writev separately.
But it does use writev on the socket.
tag and a bunch of unchanging data after it.
You only see it once in this screenshot, but it was written from the same memory location in subsequent requests.